Four condition monitoring best practices to turn data into action

Over the years, the price for data storage has dropped dramatically. This rapid change in price — coupled with an equally dramatic decrease in the cost of measuring, transmitting and storing data — have made it easier than ever for organizations to outfit their assets with data collection technologies to improve reliability across the plant and enterprise.
While there can be little doubt that better asset health visibility is an improvement in modern process manufacturing, the ability to rapidly collect and store data can quickly generate new burdens if not approached thoughtfully.
Reliability teams need to do more than just collect data; they also need to make that data useful. Historically, that meant performing regular, manual data collection rounds to collect data — often weekly or monthly — and transferring that data back for analysis to identify areas of the plant in need of improvement. While plants have implemented more automated data collection processes through the years, the need to analyze that data and turn it into valuable information remains. This task can be difficult because asset data stored without a plan can quickly increase the cost and the complexity of condition monitoring.
By following a few best practices, reliability teams can more quickly and cost-effectively turn condition monitoring data into actionable information to improve operational excellence across the plant and enterprise.
Best practice #1: Carefully manage storage rates
When plants relied primarily on manual rounds for data collection, the amount of data they were able to store was typically limited by how fast technicians could finish walking around the plant inspecting each asset on their list. This process often left analysts craving more frequently collected and more detailed data for improved tracking and trending of machine health.
Now that new automated collection technologies such as wireless sensors, online monitoring systems and edge devices have enabled real-time monitoring of assets, the floodgates of data have been opened. Hypothetically, reliability teams could go from collecting asset data once a month to once a minute or faster, ensuring they never miss a single piece of data.
However, blindly opening these floodgates presents a new set of problems. Modern storage media may be inexpensive, but that expense can quickly escalate with an exponential increase in the amount of data collected. Moreover, if the reliability team is storing collected data in the cloud, which is becoming more common, costs will increase even more rapidly. And the impacts of overly aggressive data storage extend beyond cost.
Storing data without regard to its value can drown critical data points in a sea of nonessential information because every insignificant stored data point is one more an analyst must spend time filtering out to identify more critical content.
Excessively frequent collection of data from devices can limit the number of assets the reliability team can support in real-time. Network bandwidth is limited and can become a bottleneck if every device is sending data for storage every second.
Instead of storing every piece of asset health data possible within the limitations of the organization’s hardware and software, reliability teams are often better served by developing a data storage strategy based on asset criticality. In such a configuration, the most critical assets for safety and continuous operation should both collect and store data far more frequently than essential machines and balance of plant equipment (Figure 1).

For example, if an asset’s mean time to failure is 90 days, storing health data every week should be more than sufficient. Additionally, the best condition monitoring equipment also features store-on-alert functionality, meaning that in any alert situation, data will be stored regardless of the set frequency.
With store-on-alert technology, if the reliability team stores data once a week on Mondays but the asset has an alert on Tuesday, the team will still get another stored reading as the store-on-alert functionality kicks in. In addition, store-on-demand functionality allows users to manually initiate data collection should something prompt them for data outside the normal collection schedule.
Best practice #2: Take advantage of predicate capability
The earliest continuous condition monitoring technologies collected data constantly, regardless of equipment status. For assets that run all the time, these settings often still make sense. However, there are many assets commonly running in plants intermittently, and collecting and storing data on those assets when they are down contributes significantly to data overload.
Today, reliability teams can use predicate condition monitoring to define the exact machine states under which they want to collect data. For example, consider two redundant feedwater pumps, feedwater one (FW1) and feedwater two (FW2), running in a plant, with both monitored continuously by condition monitoring devices. If FW1 is running FW2 is idle, and vice versa (Figure 2).
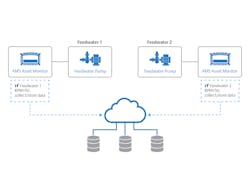
If no predicate conditions are set on the pumps, condition monitoring technologies will collect and store data on both FW1 and FW2 whether they are operating or not. Ultimately, an analyst trying to identify an issue or monitor machine health will have to sift through data to determine if a machine was running or not. This is time consuming enough when the non-running pump is transmitting “empty” data, but it can become even more complex and time consuming when crosstalk causes both pumps to send non-zero values, such as when the two pumps share a common header and vibration travels through the piping.
Reliability teams using predicate monitoring can set condition monitoring devices to take data — such as a tachometer signal — to identify specific conditions under which to collect data. In the above example, if either FW1 or FW2 is running below a set RPM threshold or not running at all, condition monitoring technologies will not collect data, ensuring data is stored only for the running pump. Moreover, teams can define exact states under which to collect data for identifying the root cause of complex issues that only occur under certain operating conditions.
Best practice #3: Use edge analytics and custom alerts to screen data
Limiting the amount of condition monitoring data stored through criticality-based policies and predicate monitoring will contribute significantly to reducing the workload of analysts, but plants without a deep bench of experienced analysts will still benefit from more assistance.
The most advanced continuous condition monitoring technologies on the market today also provide edge analytics capabilities to turn raw data into actionable information. These devices pre-filters data for technicians and analysts, helping them spend less time analyzing and more time solving problems (Figure 3).

For example, tools such as Emerson’s AMS Asset Monitor perform analytics at the device using advanced analytics technologies and rules-based capability to identify common defects. Instead of having analysts spend time poring over spectrum and waveform data, analysts and non-analysts alike can instead receive reports and alerts in real-time from edge analytics devices, viewable on any device capable of hosting a web browser — such as a laptop, smartphone or tablet. The easy-to-understand machine health condition displays sent by these devices make condition monitoring useful, even to sites without analysts that still need to monitor asset health for reliable uninterrupted production.
Best practice #4: Eliminate silos with a single storage location
As reliability teams implement more sensing technologies across the plant and enterprise, a common problem is siloed data. Instead of having all reliability data in one database, teams are forced to use different products from different vendors, often running on a variety of systems and interfaces.
Not only does siloed reliability data introduce complexity and delays into identifying and resolving reliability issues, it also makes it difficult to collaborate and share reliability data with other systems the organization may have in the cloud for big data analytics. However, a recent move toward open protocols such as OPC UA has made it easier to manage all plant reliability data from a central location. This trend also simplifies the movement of information from a wide range of disparate devices into the cloud to see bigger trends and make better organization-wide decisions.
Today, many organizations are moving to centralized monitoring from a single machinery health database that collects critical data from all the plant’s many devices. Using these tools, analysts and technicians can access a single graphical view to see all their condition monitoring and asset health data. These machinery health systems are persona-based, making it easy to configure information presented at the user level so each team member receives data relevant to their unique position.

By bringing all condition monitoring data into a single location with a standard interface, reliability teams can more easily collaborate by sharing notes, advice and media to help solve problems more quickly, making it easier to achieve operational excellence with a smaller staff.
Condition monitoring is not one-size-fits-all
It is easy to understand how technicians and analysts, once starved of the data they desired, would jump at the opportunity to collect any and every piece of data now available. However, a thoughtful condition monitoring strategy is required to prevent overload.
Even when storage capacity seems nearly unlimited, as with data lakes and cloud technologies, managing storage rates with criticality-focused collection and predicate rules will help keep costs low, while also streamlining data analysis for better visibility and improved health across the facility. Coupling these strategies with edge analytics and centralized condition monitoring tools to break down data silos ensures even small teams can keep a plant running at peak efficiency.
Brian Overton is the sales enablement manager and subject matter expert for machinery health products for Emerson. Having been with the organization for over 30 years, Brian’s background has been broad and vast, covering all aspects of reliability maintenance. Prior to his tenure with Emerson, he proudly served in the US Navy as a nuclear-trained electrician where his foundational knowledge of reliability maintenance was established. All of these years of experience are relied upon when it comes to product and program development, both internally and with customers. Brian has a Bachelor of Science in Business Administration Information Systems: Application Development from Liberty University.
Drew Mackley has over 25 years of experience in the predictive maintenance industry. In that time, Drew has worked with customers to establish and grow machinery health management programs in a variety of industries and locations around the world. He is currently working with customers and other industry professionals on incorporating best practices and modern technologies in their asset monitoring digital transformation journey for efficiency, safety, and performance improvements. Drew has a Bachelor of Science in Electrical Engineering from the University of Tennessee.
Emerson
About the Author
Brian Overton
Sales enablement manager and subject matter expert for machinery health products for Emerson
Brian Overton is the sales enablement manager and subject matter expert for machinery health products for Emerson. Having been with the organization for over 30 years, Brian’s background has been broad and vast, covering all aspects of reliability maintenance. Prior to his tenure with Emerson, he proudly served in the US Navy as a nuclear-trained electrician where his foundational knowledge of reliability maintenance was established. All of these years of experience are relied upon when it comes to product and program development, both internally and with customers. Brian has a Bachelor of Science in Business Administration Information Systems: Application Development from Liberty University.
Drew Mackley
Drew Mackley has over 25 years of experience in the predictive maintenance industry. In that time, Drew has worked with customers to establish and grow machinery health management programs in a variety of industries and locations around the world. He is currently working with customers and other industry professionals on incorporating best practices and modern technologies in their asset monitoring digital transformation journey for efficiency, safety, and performance improvements. Drew has a Bachelor of Science in Electrical Engineering from the University of Tennessee.