Self-service predictive analytics: An industrial fortune teller

The idea behind Predictive Maintenance (PdM) is nothing new — manufacturers have been using techniques to analyze and predict equipment behavior to reduce or even eliminate unexpected costs and resources for years. According to a report by Deloitte, PdM, on average, increases productivity by 25%, reduces breakdowns by 70% and lowers maintenance costs by 25%.1 Companies with successful PdM strategies can also see reductions in risks associated with health and safety, along with increased revenue.
Effectively executing a successful PdM strategy, however, doesn’t come without challenges. Aside from being time-consuming and complex, a major challenge is your plant’s data itself — particularly the ability to make sense of the data mountain you're sitting on and ensuring your process experts can properly analyze it.
Luckily, techniques surrounding industrial production and PdM have evolved tremendously, especially over the last decade. Advanced analytics methods such as diagnostic, visual and predictive analytics, when combined with machine learning algorithms, can be useful, for example, in providing time-series industrial data to even further leverage Industrial Internet of Things applications. And now the rise of Industry 4.0 has given way to a new, self-service approach toward advanced analytics that allows subject matter experts to analyze, monitor and even predict operational behavior themselves, without the need for a team of data scientists or extensive training.
Predictive analytics DIY for engineers
Predictive maintenance solutions have traditionally involved data scientists or central improvement experts for building comprehensive analytics models. Aside from being costly and time-consuming, this way of working has other major disadvantages: it creates a bottleneck in the organization, underutilizes subject matter experts and leaves many (smaller) predictive analytics cases unaddressed.
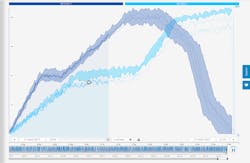
A new, integrated and more efficient approach is self-service analytics. With this novel method, there is no need to create a cost-intensive data model. It doesn’t require data scientist expertise to use the software, nor does it require an extensive overhaul to your existing infrastructure. The insights into your process and asset behaviors are based on a wealth of historical and real-time data, and with this information, subject matter experts can take proactive measures to reduce downtime and avoid unnecessary risks. It also removes the need for IT involvement, so your process experts can simply get started and focus on value generation from the first minute of deployment. With this approach, 98% of assets can be monitored, too, as opposed to just 12% of most critical assets, which is often the case.
Predictive analytics has traditionally been about defining the scope of prediction, collecting the data, developing and testing a data model, validating the outcomes and deploying the predictive model to the organization. With self-service analytics, almost all of these steps can be skipped.
For example, self-service analytics can be used to create fingerprints using any variety of signature patterns found in the past. By using defined fingerprints for event-based prediction, automatic alerts can be sent to the appropriate stakeholders, such as control room personnel or field engineers, to take appropriate action in the event of process deviation. The notifications can even include recommendations for mitigating actions.

It can also be used for hypothesis generation for diagnosing process issues that fuel new event-based predictions. Behavior in one part of the production line can then be correlated with (future) behavior downstream. Automatic regression of process parameters is, for example, used to make soft sensors to predict product quality.
Asset performance & predictive maintenance
Asset performance, or Overall Equipment Effectiveness (OEE), depends greatly on the process in which the asset operates. Instead of just using equipment-related sensor data for performance analysis, all process-related sensor data should be taken into account. This is called “contextualization of asset performance with process data,” and with this, data-based predictive maintenance becomes possible.
The goal of predictive maintenance is to be able to perform maintenance at a time when it is not only the most cost-effective, but also when it will have the least impact on operations, and that requires a good understanding of the process performance. Process engineers (or other subject matter experts) are in the best position to analyze good and bad performance. By representing all sensor-generated data in a graph, especially when multiple tags need investigation, it is hard to find correlations. Self-service analytics tools provide descriptive analytics features to quickly explore and filter data visually and search through large amounts of process data (easily up to multiple years of historical data). The advanced analytics capabilities also allow the user to do root cause analysis (RCA), test hypothesis (discovery analytics) and quickly find similar behavioral occurrences.
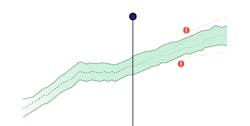
Through diagnostic analysis, the process engineer can understand effects of process changes (comparing before vs. after) and find potential influence factors for a specific issue. By understanding the difference between good and bad behavior, the base is created to understand when maintenance is required. With this information, monitors can be created to safeguard best operating zones and maintenance can be predicted.
Practical use cases with self-service predictive analytics
Heat exchanger fouling
Besides calculating the possible trajectories of the process and predicting future evolutions of key variables, self-service analytics can also be used to monitor degrading asset performance over time. One use case is related to the heat exchanger fouling. In a reactor with subsequent heating and cooling phases, the controlled cooling phase is the most time-consuming, and it is almost impossible to monitor fouling when the reactor is used for different product grades with different recipes required for each grade. Fouling of heat exchangers increases the cooling time, but scheduling maintenance too early leads to unwarranted downtime and scheduling too late leads to degraded performance, increased energy consumption and potential risks.
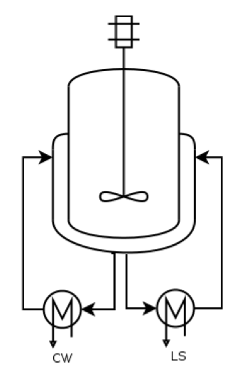
In the instance of the production of a polymer, a monitor was set up to look at the cooling times of a company’s most highly produced products. If the duration of the cooling phase starts to increase, a warning is sent to the engineers who can then schedule timely maintenance. The gained benefits are extended asset availability, predictive maintenance leading to operational and maintenance cost reduction, and reduction of safety risk. For this customer case, the overall impact was 1%+ overall revenue increase of the entire production line.
Pump status monitoring
Within a water distribution network, only 5% of all pumping stations were responsible for more than 50% of the total maintenance costs. With the self-service analytics solution, expected malfunctioning of pumps could be detected by rising hydraulic heads and increased energy consumption.
Using scatter plots and fingerprints, the pumps were monitored to perform most efficiently and reliably within their best operating zones. Soft alarms were added and users are now notified when equipment is expected to fail, allowing them the time to take proactive action. This has improved asset reliability and lowered overall operational costs. Additionally, dashboards can be created to monitor the statuses of the pumps.
Drum maintenance
One last use case took place at a petroleum refinery where hydrogen fluoride is used as a catalyst in the alkylation unit. It is regenerated in a stripper that is drained to a drum multiple times a day based on the level in the column. After a few days, four thermocouples at different heights in the drum indicate when the drum is full and must be drained.
With discovery and diagnostic analytics, the engineers could show that the time until the drum is full (indirectly) depends on the acid flow to the stripper column. Based on the analysis, it can now be predicted when the drum will require maintenance. This provides plenty of advance time to schedule the drainage work and lower related maintenance costs.
Conclusion
Traditional predictive maintenance is often time-consuming and isolated from the subject matter experts — and consequently only typically used on the most critical assets. Common pitfalls and challenges such as model complexity can now be avoided through the intuitive workflows of self-service analytics. With this approach, the day-to-day process experts can be empowered to use their knowledge with use of the information hidden in time-series data without dependency, and with this they can drive their own predictive maintenance strategies for all equipment within the production line.
This method can be your crystal ball, and the information it provides can result in a reduction of maintenance-related labor costs, reduction in unexpected failures or shutdowns, reduction in repair and overhaul time, and an increase in uptime. If data is considered to be “the driving force behind the predictive maintenance engine,”1 the people analyzing and interpreting the data need to be fully equipped to be an effective pit crew.
References:
1. Deloitte, Taking Pro-active Measures Based on Advanced Data Analytics to Predict and Avoid Machine Failure https://www2.deloitte.com/content/dam/Deloitte/de/Documents/deloitte-analytics/Deloitte_Predictive-Maintenance_PositionPaper.pdf
Nora Villarreal is a marketing specialist at TrendMiner, a company whose mission it is to democratize analytics within process industries. With nearly 15 years of marketing experience, she has achieved success with companies such as Ingrain, the American Bureau of Shipping and ExxonMobil.
About the Author
Nora Villareal
marketing specialist at TrendMiner
Nora Villarreal is a marketing specialist at TrendMiner, a company whose mission it is to democratize analytics within process industries. With nearly 15 years of marketing experience, she has achieved success with companies such as Ingrain, the American Bureau of Shipping and ExxonMobil.