5 key enablers to better plant performance
The word “enabler” often has a negative connotation because it is commonly used to describe someone who helps another person travel a destructive path. However, enablers are not limited to negative influences. In fact, an enabler can facilitate positive results. Part of the cure for people on destructive paths is to distance themselves from negative influences and surround themselves with those who enable positive change. This concept is also true in business. By surrounding projects and initiatives with positive enablers, organizations can strengthen their abilities to succeed and, in some cases, transform negative situations into positive ones.
Five key underlying maintenance- and reliability-based enablers that can have significant impact on plant performance are:
- Eliminating catastrophic failures
- Minimizing functional failures
- Eliminating self-induced failures
- Minimizing all shutdowns
- Relying on data-driven decision making
Each of these enablers is dependent on the others, with the earliest steps creating a foundation for the others. By examining and implementing these key enablers, organizations can take the steps necessary to significantly improve plant reliability and performance.
1. Catastrophic failures are predictable & preventable

The plant floor is a busy place, but ignoring a pump that has decreased pressure or a gearbox that displays excessive vibration does not save maintenance time. Instead, it creates an environment where the device will likely fail during production, resulting in a situation that will take many more man hours to fix, and increase stress levels throughout the organization.
To consistently prevent catastrophic equipment failure, organizations must engineer preventive maintenance procedures that measure the condition of assets quantifiably. Trends in conditions such as belt tension, chain wear and differential pressure should all be tracked. In addition, use of equipment and applications such as Emerson’s AMS 6500 monitor or AMS 2140 portable machinery health analyzer for vibration analysis and monitoring, as well as devices for infrared thermography, motor circuit analysis and ultrasonic detection, to name a few, are key elements of eliminating catastrophic failure.
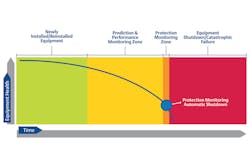
Reactive maintenance costs are typically 50 percent higher than planned maintenance costs. A potential failure curve (see Figure 1) illustrates the risk of relying solely on protection monitoring without taking advantage of the benefits of predictive and performance monitoring. Because protection monitoring typically trips immediately before or after catastrophic failure, it leaves little to no time for planned maintenance, increasing the cost of scheduling service contractors, ordering parts, assigning personnel, production outages and more.
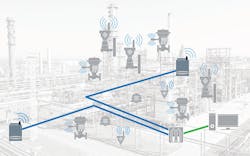
Recently, considerable interest and energy have surrounded the concept of the Industrial Internet of Things (IIoT), which takes the concept described above to significantly new levels by deploying smart sensors and technology on a wide range of assets deep into the asset base and utilizing advanced data analytics tools and techniques to correlate all available data. This concept moves condition-based monitoring (CBM) from wired to wireless, and periodic, manual route-based data collection to continuous and online (see Figure 2). The concept of IIoT allows users to detect early warning of failures, in some cases months in advance of traditional predictive maintenance techniques, thereby allowing even more time to introduce early corrective action and prevent functional failure.
2. Recurring failures are more than just an annoyance
It is a mistake to assume that small, recurring problems in equipment will never amount to any significant downtime and are not worth tracking. These functional failures, the point at which an asset no longer performs its intended function at the intended level, may not ever result in downtime, but even so, the collective impact on production can result in losses that are significant over time.
When a pump that should pump 100 gallons per minute only pumps 90, it is easy to dismiss the functional failure as noncritical. After all, production continues to run with only a marginal impact on throughput. However, if that impact continues hourly, daily or even weekly over the course of six months to a year, the lost production can be staggering.
Much of this oversight stems from the fact that many organizations do not monitor technology deeply enough. Most organizations focus only on catastrophic risk to critical pieces of equipment. While all monitoring is valuable, critical equipment cannot be monitored heavily at the expense of all other plant assets. By taking advantage of tools that give a snapshot of asset health deep into the plant’s asset base, organizations can have a major positive impact on functionality.
It is also essential to recognize the role that operators and management play in sustaining reactive maintenance culture. When operators and management want to make production goals, they may push for quick fixes or for continued – even increased – operation, despite the indication of developing functional failures. The production gains that come from operating under such a policy are an illusion. The organization may gain production now, but by ignoring the root problem, it will most certainly pay for it later.
3. When we are the problem
Among all the practices that stand in the way of operational success, self-induced failure can be the most difficult to eradicate. It is easy to get used to substandard maintenance practices that sneak in to day-to-day operation under the guise of getting things done as quickly as possible. Unfortunately, unplanned and ill-prepared maintenance often causes more problems than it solves.
In poor-performing organizations, self-induced failures can make up as much as 75 percent of the failures the organization experiences. However, getting at the root cause of these failures is not as simple as it seems. An organization can provide its maintenance technicians the best in tools, training and diagnostic equipment, but if technicians are constantly under pressure to complete repairs in emergency situations (or not at all), they will not have the opportunity to put all that advanced technology to use. Instead, the organization will continue to only catch failures when they become severe, leading to a highly reactive organization that can only deal with the next emergency as opposed to a robust, proactive organization that is focused on eliminating the causes of problems before they occur. This problem is commonly seen in emergency part replacements in rotating equipment such as gearboxes, fans and grinders. When technicians are under pressure to get a part replacement done as quickly as possible, the alignment step is often skipped. Instead of checking tolerances and using a laser alignment tool, hurried technicians simply slap the device back together again to get it running as quickly as possible. While such measures may get equipment up and running, improper procedures will nearly always lead to a shorter life span.
But self-induced failures are not limited to technicians who are under pressure. Even in a controlled shutdown situation, if technicians are not provided with the proper maintenance procedure, they can cause more problems than they solve.
If a work request simply says, “replace pump,” technicians have not been given all the information they need. If a good process has not been established that works the request into a maintenance schedule, provides a written procedure, lists and orders the proper parts, and lists tools required and details like alignment and tolerances, etc., the result will be an inefficient job manifested by multiple trips to the storeroom and less precision on installation.
Properly planned work is two to three times more efficient than unplanned work. When high-quality, standardized work procedures have been created, technicians have all the information they need to do a job properly, and organizations are more likely to get an efficient, consistent and repeatable job no matter which qualified craftsman does the work.
4. Shutting down means wasting time
At the heart of tracking down and eliminating all points of failure in a manufacturing plant lies one goal: minimizing all shutdowns. Shutdowns can eat up 1 percent to 10 percent of available production time, resulting in nonproductive hours that cannot be recovered. As a result, organizations try to schedule necessary shutdowns to maintain control over production.
What organizations often fail to realize is that scheduling a shutdown should still be a data-driven decision. Calendar-based downtime with the intention of mitigating failure does not truly provide value because equipment does not fail on a predetermined schedule. Instead of planning shutdowns, maintenance teams must use data to create work orders that will allow technicians to perform quality repairs that avoid functional and catastrophic failures.
Technicians must also have tools and information to enable learning from the repair process. An organization’s computerized maintenance management system (CMMS) must be kept organized and up-to-date, accurately reflect the equipment in the plant, and provide accurate and completed foundation data on assets, parts, maintenance procedures and failure coding. A properly maintained and updated CMMS will enable an efficient work management process that will ensure jobs are completed quickly and accurately.
In addition, the practice of doing overhauls on equipment often causes induced failure for a range of reasons (see Figure 3).
5. Letting data drive
Organizations that focus on managing by data development can measure and track trends and performance, which can be key tools to operational success. To accomplish this, however, quality data must be collected at every level, which means fostering buy-in to data collection at all levels of the organization.
Everyone has a role in data management. When a planner writes a work order, it should be written to the right piece of equipment. In addition, the planner has a responsibility to ensure that the work order is accurate and thorough, with the right parts, tolerances and procedures clearly spelled out. When the organization makes an equipment change, it is essential that the master equipment list is updated.
The technician completing and documenting a job needs to use the right failure codes so the organization can have proper tracking and trending of equipment failure. Technicians should also be sure to note any additional issues noticed during repair to help keep track of overall equipment functionality.
Plant management (plant manager, operations, maintenance) has a responsibility to track work history to fully understand where the major issues impacting reliability are and where the maintenance spend has been going. Without accurate data collection, managers cannot report these critical metrics. If this data are bad or nonexistent, it becomes difficult to manage budgeting and purchasing.
When all members of the organization understand their roles in the collection and maintenance of key data, collected data become more reliable and functional.

Moving toward a more reliable future
To varying degrees, most organizations have some level of initiative to improve plant performance and reliability. These initiatives could be corporate-wide, plant-specific or driven by a few individuals. No matter where a company is in its attempts to monitor machinery health, focusing on the enablers discussed in this article will create an environment to drive improvement more easily. Predictive maintenance and machinery health monitoring products are available to target the key enablers that every organization should employ to improve overall reliability. When an organization embraces these key enablers as part of everyday plant culture, it will run more efficiently and more reliably than ever.
Dennis Belanger, CMRP, is a director and life sciences practice lead for Emerson Reliability Consulting. His 30 years of experience includes executive level, maintenance and reliability roles at Mobil Chemical, The Quaker Oats Company and with the U.S. Navy. Belanger may reached at [email protected] or 203-494-5219.
Emerson Reliability Consulting